inlfuxdb源码分析-文件结构(二)
存储数据结构
influxdb的存储引擎为改进lsm tree, 叫做tsm tree.
关于lsm tree其核心的思想就是:将对数据的修改增量保持在内存中,达到指定的大小限制后将这些修改操作批量写入磁盘。 改随机写为顺序写,对写多读少的场景又很强的优化效果
参考:
文件结构
tsm文件
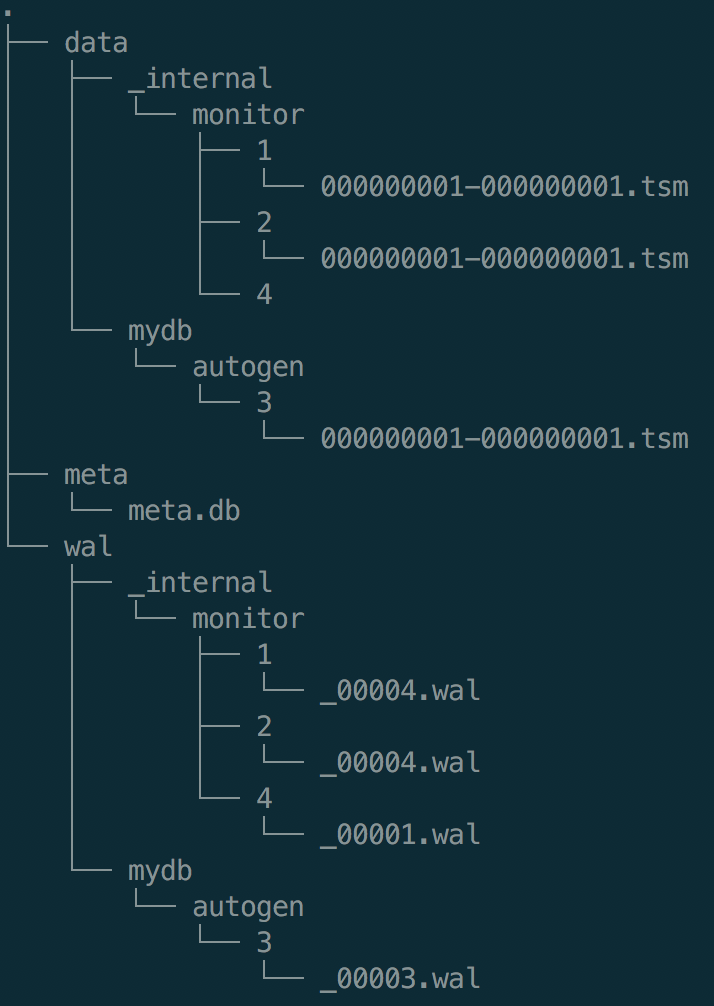
一个tsm文件的构成:Header, Blocks, Index,Footer

Header
4bytes Magic number, 1byte Version
MagicNumber uint32 = 0x16D116D1
Version byte = 1
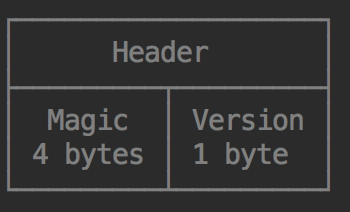
Blocks:
Block 由CRC校验4个字节, 已经Data 字节组成。 Data 的数据解压后的格式为 8 字节的时间戳以及紧跟着的 value,value 根据类型的不同,会占用不. 同大小的空间,其中 string 为不定长,会在数据开始处存放长度,这一点和 WAL 文件中的格式相同。
Index
Index 存放的是前面 Blocks 里内容的索引。索引条目的顺序是先按照 key 的字典序排序,再按照 time 排序。InfluxDB 在做查询操作时,可以根据 Index 的信息快速定位到 tsm file 中要查询的 block 的位置
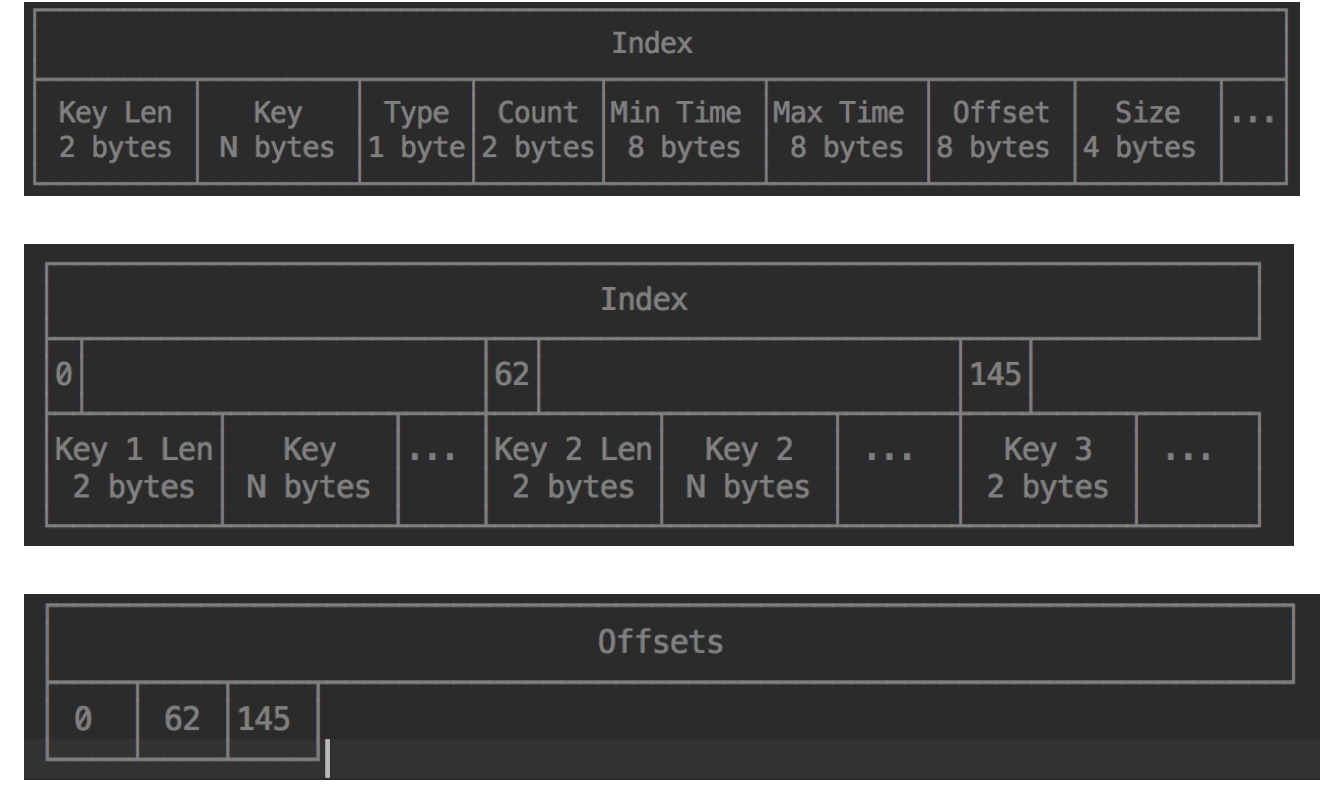
查找时, 会根据Key做二分查找, 找到key在block中的偏移,取出数据。
