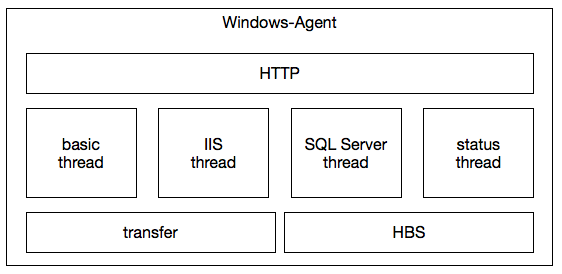
kiss原则
KISS, an acronym for keep it simple, stupid, is a design principle noted by the U.S. Navy in 1960.
最近在生产环境大规模上量 VictoriaMetrics 作为监控后端时序存储,同时研习了一下VictoriaMetrics的代码;
不得不说, Valialkin大神的代码确实牛逼,具体代码和性能以后有时间会分享,这里主要看到文档中对kiss原则的一些描述,觉得非常到位
We are open to third-party pull requests provided they follow KISS design principle:
- Prefer simple code and architecture.
- Avoid complex abstractions.
- Avoid magic code and fancy algorithms.
- Avoid big external dependencies.
- Minimize the number of moving parts in the distributed system.
- Avoid automated decisions, which may hurt cluster availability, consistency or performance.
Adhering KISS principle simplifies the resulting code and architecture, so it can be reviewed, understood and verified by many people.
Due to KISS cluster version of VictoriaMetrics has no the following “features” popular in distributed computing world:
- Fragile gossip protocols. See failed attempt in Thanos.
- Hard-to-understand-and-implement-properly Paxos protocols.
- Complex replication schemes, which may go nuts in unforesseen edge cases. See replication docs for details.
- Automatic data reshuffling between storage nodes, which may hurt cluster performance and availability.
- Automatic cluster resizing, which may cost you a lot of money if improperly configured.
- Automatic discovering and addition of new nodes in the cluster, which may mix data between dev and prod clusters :)
- Automatic leader election, which may result in split brain disaster on network errors.
翻译
- 简单的代码和架构。
- 避免复杂的抽象。
- 避免魔改和花哨的算法。
- 避免大的外部依赖。
- 尽量减少分布式系统中组件的数量。
- 避免自动决策,这可能会损害群集可用性、一致性或性能
由于坚持kiss原则,VictoriaMetrics没有一些在其他分布式系统中流行的特性
- 脆弱的gossip协议, 可以参考Thanos中失败的尝试
- 难以理解和实现的paxos协议
- 复杂的副本方案,可能在边界条件下产生很多问题,副本方案
- 存储节点数据的自动reshuffling, 可能有损整个集群的性能和可用性
- 自动调整集群的大小(容量),如果配置不当,会花费过多的成本(资源?cpu, mem)
- 自动发现和自动向集群中添加新的节点, 可能会导致破坏pord数据(不太理解)
- 自动选主,在网络出问题的时候,会引起脑裂的灾难
###参考文档